NaiveBayes
1. Overview
A Naive Bayes classifier is a probabilistic machine learning model used for classification, the most famous implementation is email classification to identify the potential spam.
Multinomial NB algorithm is variant of Naive Bayes, it assumes features are independt, and can be applied to multiple output labels for single model.
Bernoulli is also an naive bayes algorithm mostly used for binary classifcation, and the input features must be binary variable as well (eg. True, False), each feature is considered independent.
Here, we will use Standard Multinomial NB to classify the amazon saling data, and predit an expected rating based on given features.
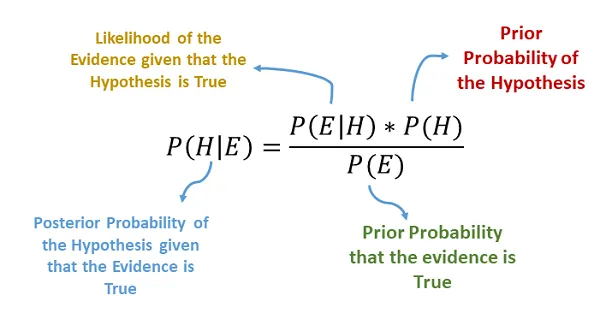
@Image Source: https://charanhu.medium.com/naive-bayes-algorithm-2a9415e21034
2. Data Prep
Here I use amazon store sales data from kaggle as the raw data.
It’s easy to find the original dataset contains lots of text data columns and inconsistent format between numerical columns.
I did following steps to clean optimize the data.
- Keep only numerical value as input feature, for navie training purpose
- Discretize ‘rating’ column, and take it as label, the continuous label output didn’t work well for NaiveBayes model.
- Clean and format Numerical data
- Normailze data with min-max scaler
Code Step: https://github.com/BraydenZheng/Product_Recommendation/blob/master/naivebayes/data_prepare.ipynb
Split training and testing data as 80%, 20% portion accordingly
The purpose of creating a disjoint split is to ensure that model only testing on unseen data during evaluation, which closely resembles real-world scenarios.
Cleaned Data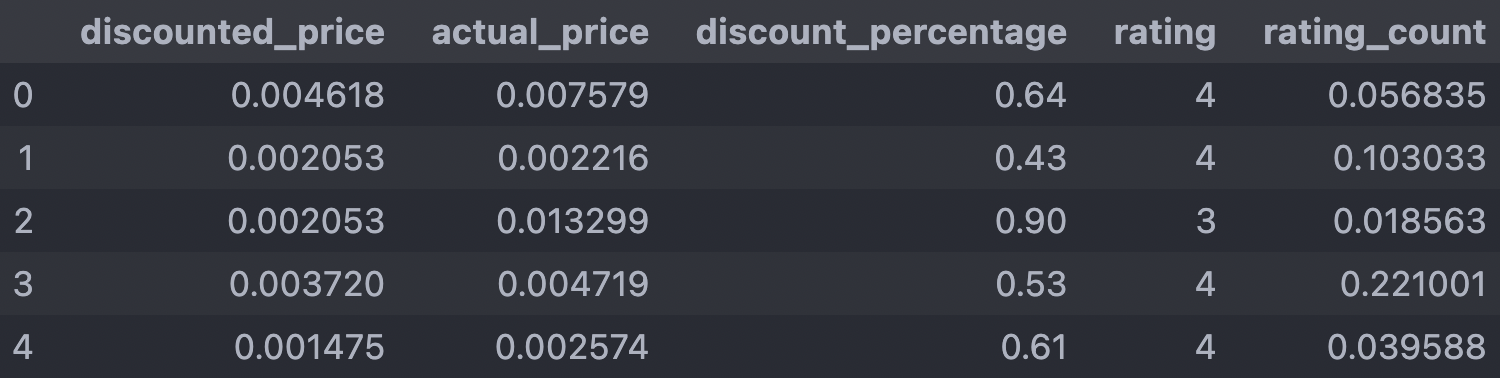
3. Code
Model training and evaluation: https://github.com/BraydenZheng/Product_Recommendation/blob/master/naivebayes/naivebayes.ipynb
4. Result
Accuracy: 0.78
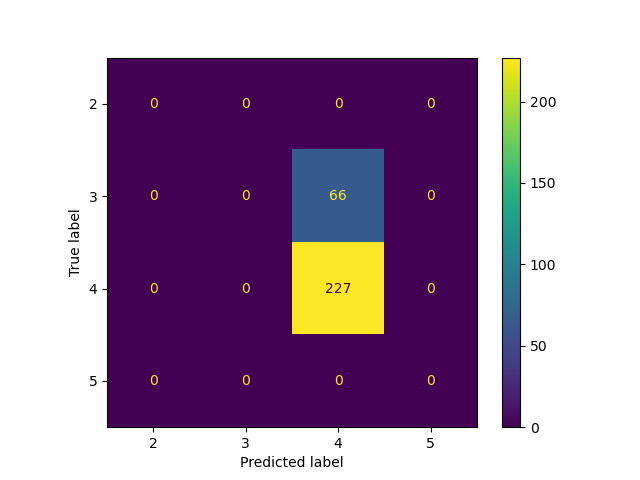
After several rounds of tuning, the model achieve the accuracy 78% on test data. The majority of data has discrete rating as ‘3’ or ‘4’, while model has good performance overall, one weakness of this model is lacking of the ability to predict label rating ‘3’, actullay that’s even not shown on predicted test data.
5. Conclusion
- Normalization matters, I got 60% accuracy for data without normalization, the accuracy rise to 78% after applying min-max scaler
- Take caution when using MNB for continuous output data. To apply MNB on continuous label, we need to first discretize data label and then feed into the model. However, discretize data sometimes cause the output label too concentrated, which leads to the weakness for model predit on margin data.