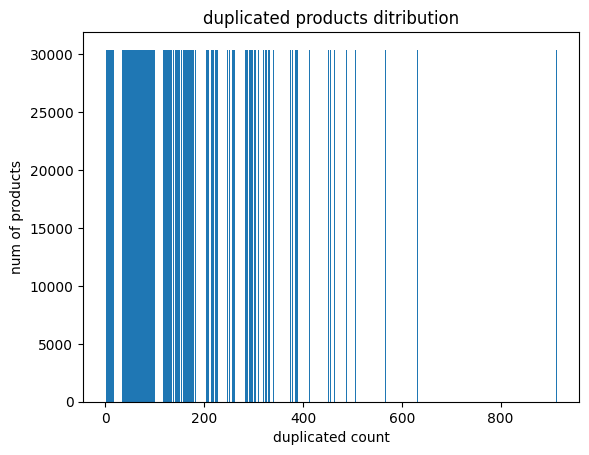
Build an image showing the num of duplcated product existed in data set, it’s tremendous
1 2 3 4 5 6 7 8 9
# Horizontal Bar Plot show duplicated count - num of products plt.bar(p_a.index, p_a.iloc[0])
plt.xlabel("duplicated count") plt.ylabel("num of products") plt.title("duplicated products ditribution") plt.savefig('img/duplicated_product_distribution.png') # Show Plot plt.show()
3.3 Merge Duplicated Data
The main focus here is merging duplicated data, making each product id unique
For those product contains multiple scores, counting an average probably be a good choice for it. The drawback is some unique fields also need to be removed (‘Text’, ‘Summary’). Since the score plays a determined factor in recommendation, removing is necessary for certain analysis.
1
df_avg = df.iloc[:, 1:5]
1
df_avg
ProductId
HelpfulnessNumerator
HelpfulnessDenominator
Score
0
B001E4KFG0
1
1
5
1
B00813GRG4
0
0
1
2
B000LQOCH0
1
1
4
3
B000UA0QIQ
3
3
2
4
B006K2ZZ7K
0
0
5
...
...
...
...
...
568449
B001EO7N10
0
0
5
568450
B003S1WTCU
0
0
2
568451
B004I613EE
2
2
5
568452
B004I613EE
1
1
5
568453
B001LR2CU2
0
0
5
568454 rows × 4 columns
1
avg = df_avg.groupby(['ProductId']).mean()
1
avg.insert(0, 'ProductId', avg.index)
1
avg.index = range(len(avg.index))
Cleaned Data generated, duplicated value eliminated
objc[5257]: Class WebSwapCGLLayer is implemented in both /System/Library/Frameworks/WebKit.framework/Versions/A/Frameworks/WebCore.framework/Versions/A/Frameworks/libANGLE-shared.dylib (0x7ffb59f48ec8) and /Applications/Google Chrome.app/Contents/Frameworks/Google Chrome Framework.framework/Versions/109.0.5414.119/Libraries/libGLESv2.dylib (0x111ded880). One of the two will be used. Which one is undefined.
[0206/204727.828076:INFO:headless_shell.cc(223)] 60469 bytes written to file /var/folders/0t/vj81lwzn36xcslx3y2f148t40000gn/T/tmp9j9u523o/temp.png
/var/folders/0t/vj81lwzn36xcslx3y2f148t40000gn/T/ipykernel_3210/869401958.py:1: UserWarning:
`distplot` is a deprecated function and will be removed in seaborn v0.14.0.
Please adapt your code to use either `displot` (a figure-level function with
similar flexibility) or `histplot` (an axes-level function for histograms).
For a guide to updating your code to use the new functions, please see
https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751
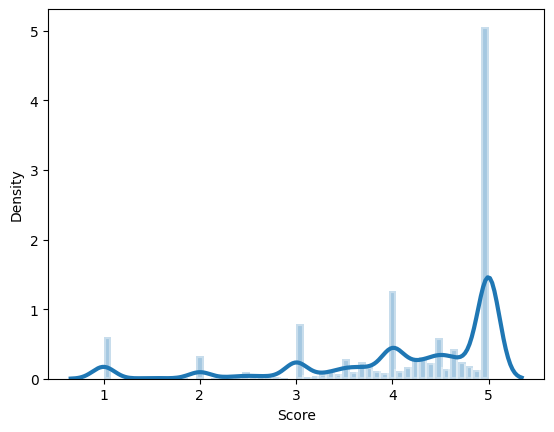
ax = sns.distplot(avg.Score, hist=True, hist_kws={"edgecolor": 'w', "linewidth": 3}, kde_kws={"linewidth": 3})
1
ax.figure.savefig('img/dist_plot.png')
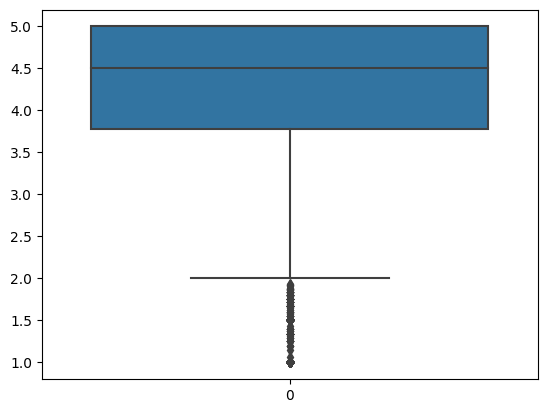
Method 2: Detect outlier based on Distribution
1
ax = sns.boxplot(avg.Score)
1
ax.set(title='Review score box plot')
[Text(0.5, 1.0, 'Review score box plot')]
1
ax.figure.savefig('img/box_plot_score.png')
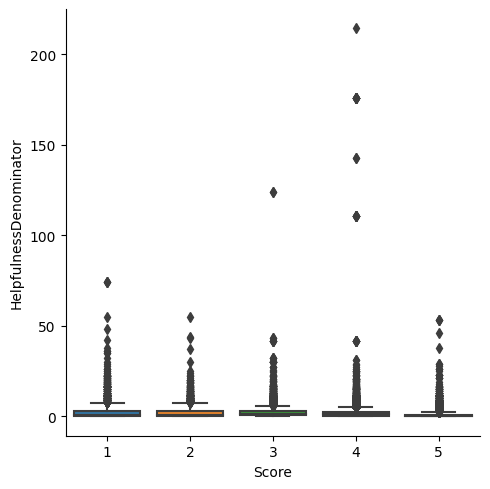
Based on graph results above, score below 2.0 can be possible outlier, however as it’s shown from second graph, the dot is super dense for those “possible outliers”, in this case, no need to remove outlier at this point.
3.5 Other visualization
1
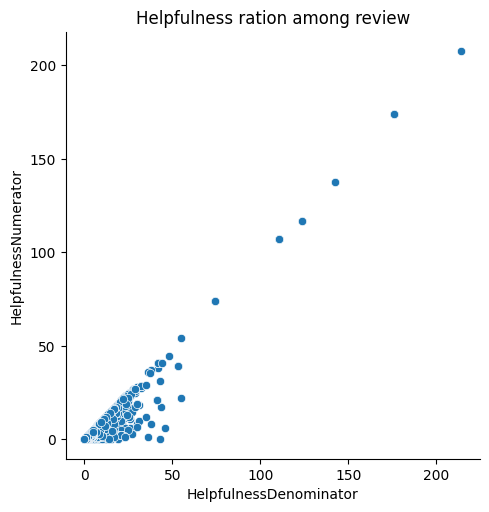
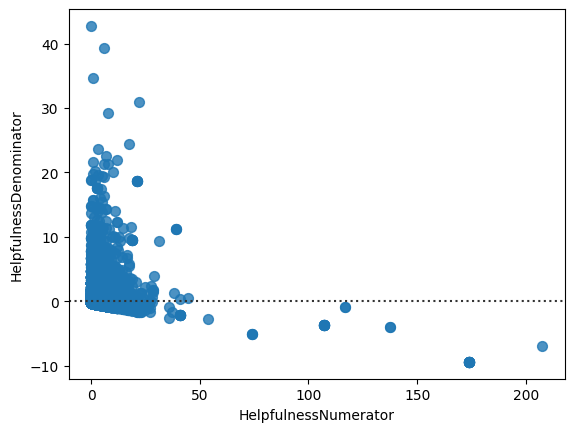
fig = sns.relplot(data = avg, x = 'HelpfulnessDenominator', y = 'HelpfulnessNumerator').set(title='Helpfulness ration among review')
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.