svm
1. Overview:
SVMs are supervised meachine learning techniques massively used in both industry and acamemics for classification, regression purpose.
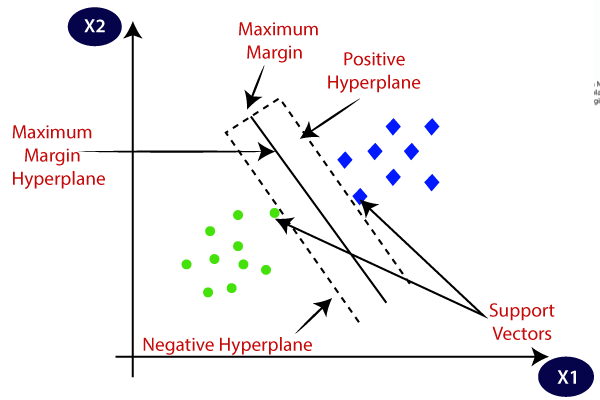
@Image Source: https://www.analyticsvidhya.com/blog/2021/10/support-vector-machinessvm-a-complete-guide-for-beginners/
SVMs belong to linear separators because they are used to find a hyperplane to separate the target class in given dataset.
For those dataset can’t be linear separated, svm use kernel trick to cast data into high dimensions and then do the linear separation. The kernel is function that computes the dot product between different points in high dimensional space. This is a crucial step as it doesn’t explicitly calculate the data points in resource expensive high dimensional space, but does it in lower space.
There are two types of most used kernels: Polynomial and RBF kernel:
Polynomial Kernel Function: F(x, y) = (x * y + r)^d. Here x and y refer to input data, r is constant, and d is polynomial degree.
RBF kernel: exp(-γ ||x - y||^2)), here γ = 1/(2σ^2), and σ is a free parameter.
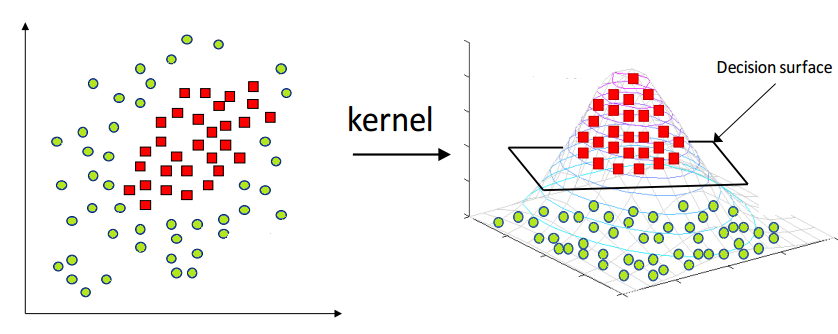
@Image Source: https://www.hackerearth.com/blog/developers/simple-tutorial-svm-parameter-tuning-python-r/
Let’s consider taking a 2D data point (x, y) and using a polynomial kernel with r = 1 and d = 2 to map the point into a high dimensional space. After expanding the formula:
The new data point pos will be after conversion.
2. Data Prep
Here I use amazon store sales data from kaggle as the raw data, the same raw data used for NaiveBayes.
It’s easy to find the original dataset contains lots of text data columns and inconsistent format between numerical columns.
I did following steps to clean optimize the data.
- Keep only numerical value as input feature, for navie training purpose
- Clean and format Numerical data
- Normailze data with standard scaler
- Outliers removal for some columns
- Discretize the rating column into 3 buckets, and take it as label, the continuous label output didn’t work well for SVM
Code Step: https://github.com/BraydenZheng/Product_Recommendation/blob/master/svm/data_prepare.ipynb
Split training and testing data as 80%, 20% portion accordingly.
The purpose of creating a disjoint split is to ensure that model only testing on unseen data during evaluation, which closely resembles real-world scenarios.
Cleaned Data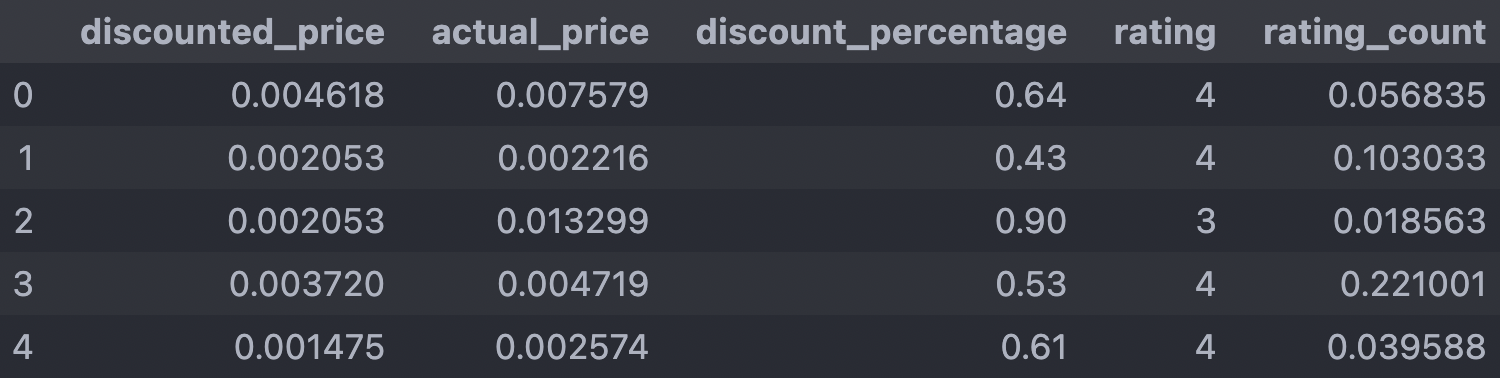
SVMs can only be used for labbled numerical data, because it relies on mathematical operation likes dot product, and kernel function for optimization also requires numerical input. For those non-numeric data (eg. text input), we need to use encoder, word embedding or other technique to convert them to numeric before passing to SVMs.
3. Code
Model training and evaluation: https://github.com/BraydenZheng/Product_Recommendation/blob/master/svm/svm.ipynb
4. Results
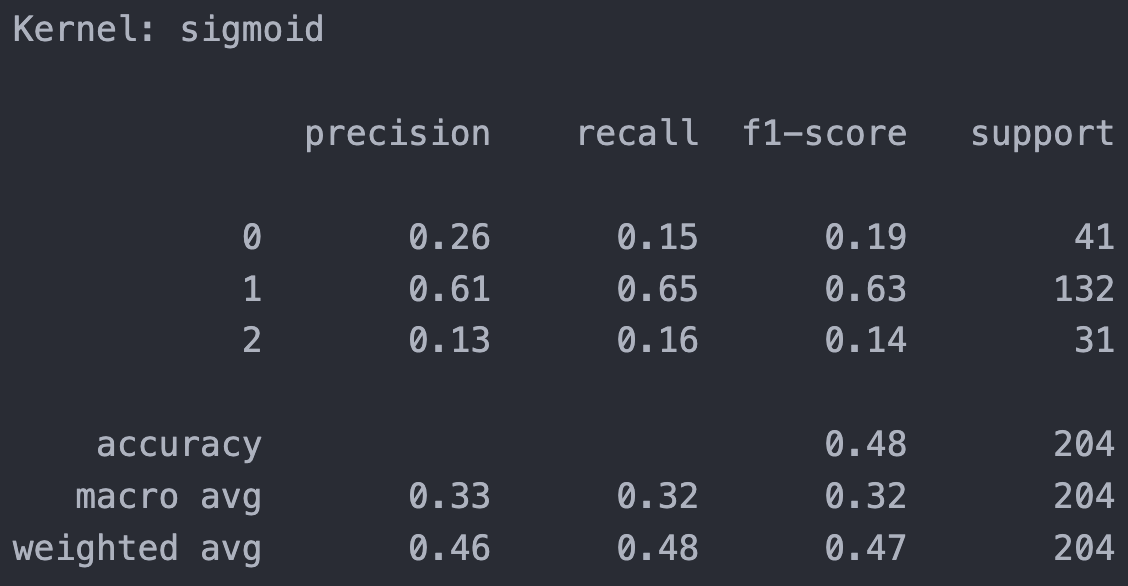
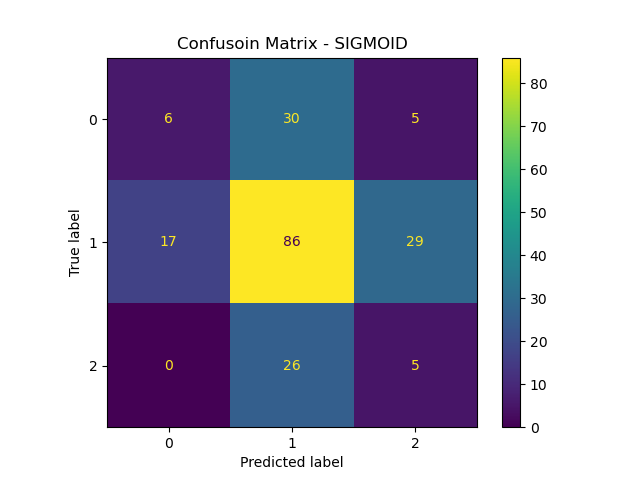
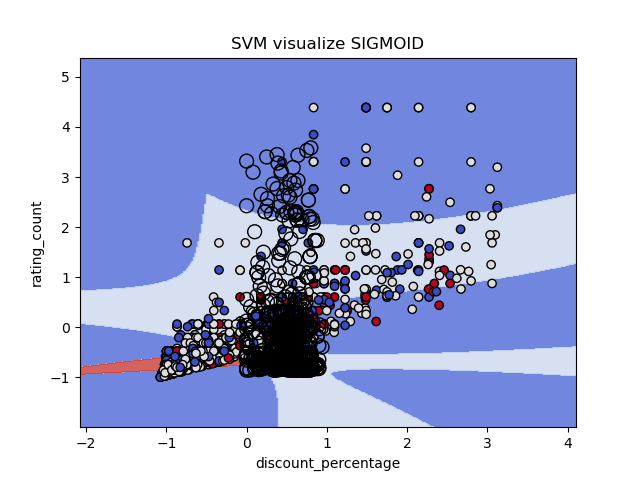
Sigmoid Kernel (cost = 1)
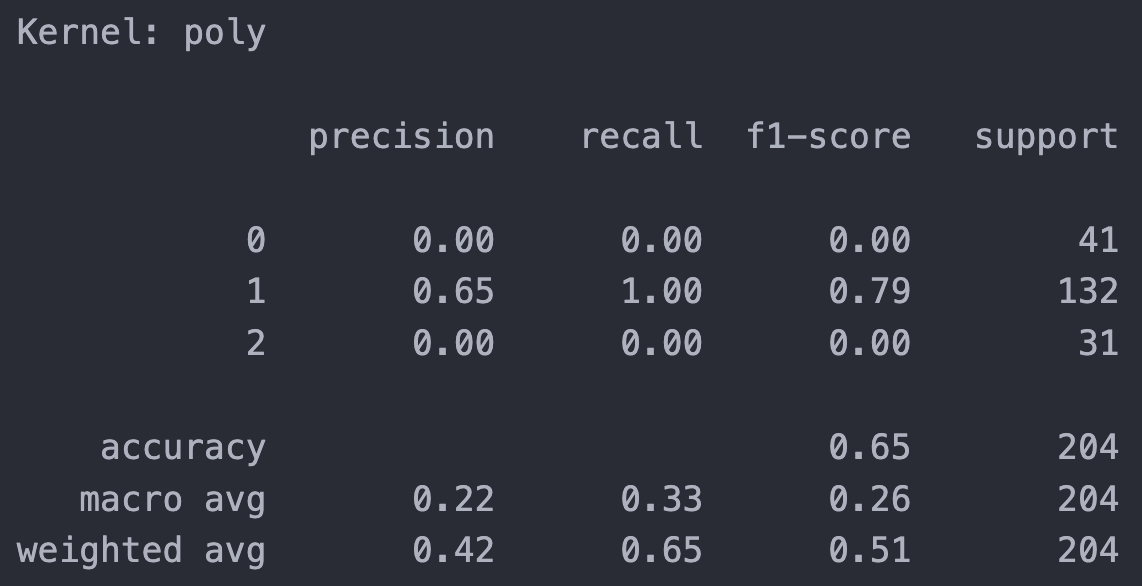
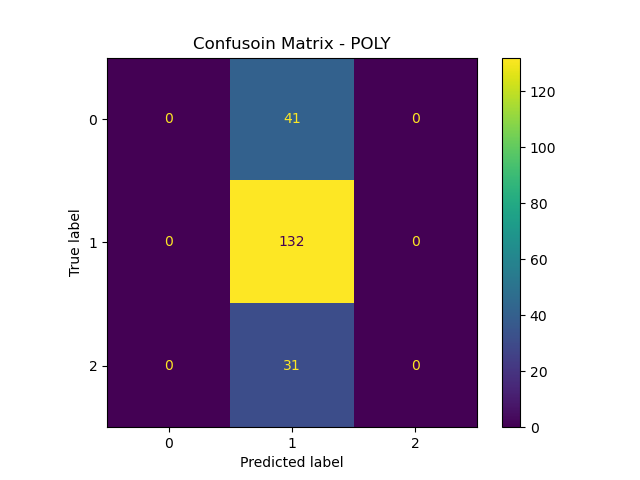
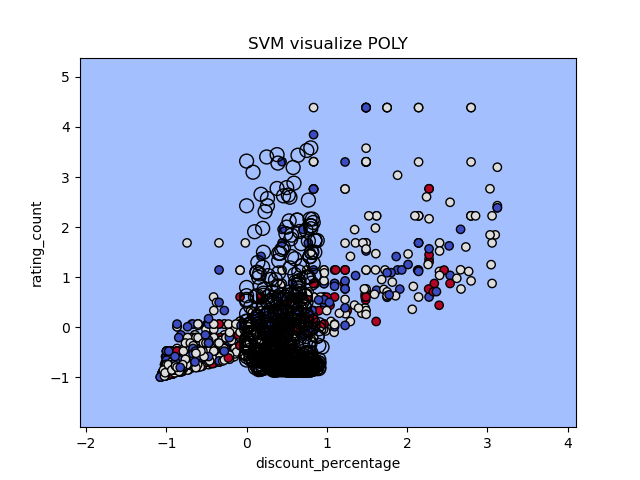
Poly Kernel (cost = 1.2)
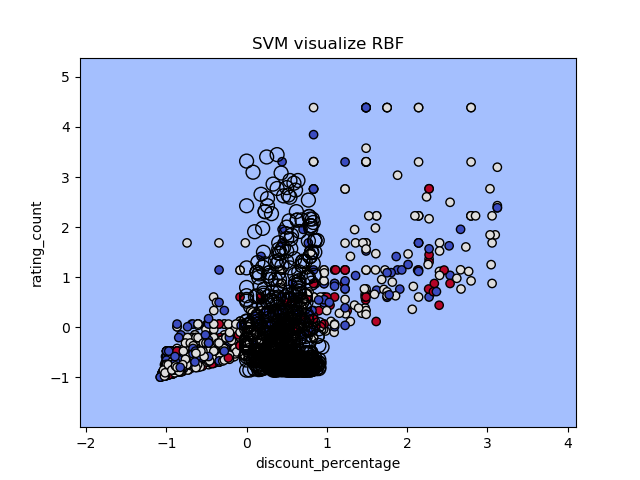
RBF Kernel (cost = 1.5)
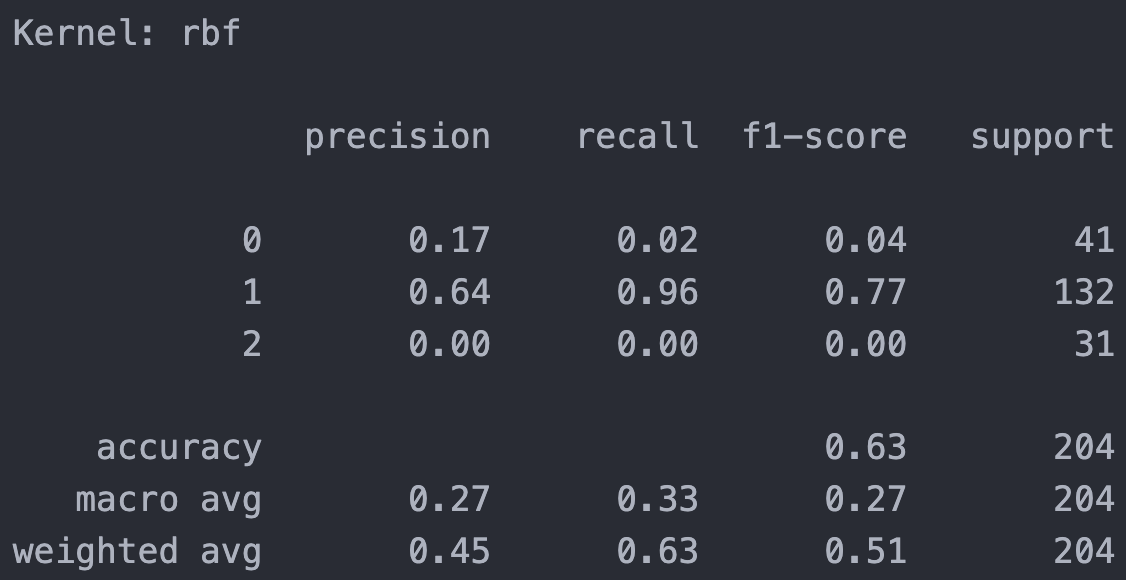
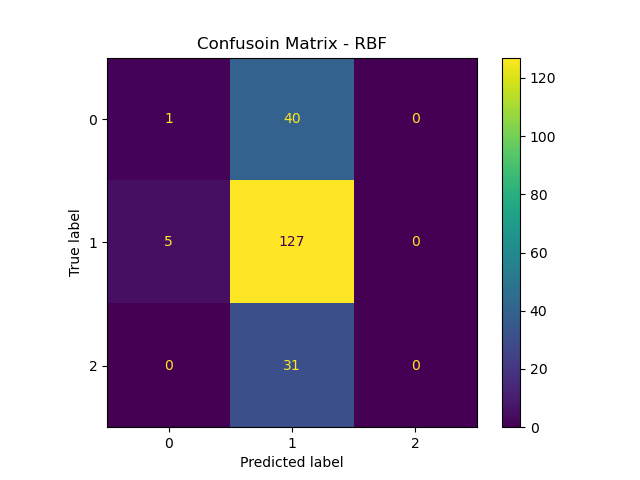
From all kernels result above, the Sigmoid kernel has lowest overall accuracy (48%) , but it performs well in rating class 0 and class 2 compared to other 2 kernels has poor recognization. The performance for RBF and poly are pretty much similar, with better accuracy but failed on class 0 and 2.
For SVM visualization (Re-train with two features), the sigmoid model have good visible boundary for all three class, while other two kernels got boundary gather together.
In general, sigmoid kernel has relative average performance on different class, while RBF and poly kernels has good performance overall and in major class, they didn’t function well in less represented class. For overall rating, I conder ‘sigmoid’ is the best one for this training purpose.
5. Conclusion
- The sigmoid model server as general model, it has the ability to take care of every input class even if it’s less represented.
- Outliers significantly influences the model performance, when I did the first run without removing outliers, all three functions has super poor result.
- While SVM is good way for classification, different kernel has significantly various performance for rating classificaiton purpose, we can change kernels to repspond different needs for the daily business.