DecisonTree
1. Overview
Decison Tree is popular ML algorithm can be applied for both regression and classification problems. The decision tree contains structure called ‘rule’ and ‘node’, where ‘rule’ is the judging condition and leaf is the decison result.
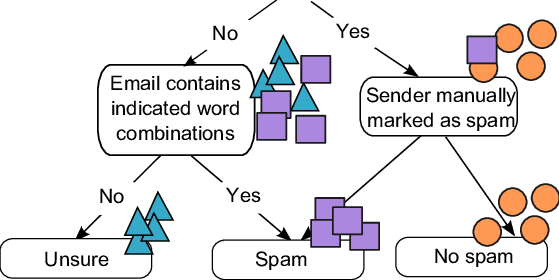
Typical applications includes email spam filter, product classification, and even stock market prediction.
GINI, Entropy, and Information Gain are all used to assist deciding the best rule to split data at each level. They are all useful tools to reduce the impurity of data node, usually we maximize the information gain to make decison tree more effective and use less depth.
Here is an example using GINI and information gain.
Assume we have 10 fruits in total, 7 as apples and 3 as banana.
Before applying any rule, the GINI is: 1 - (P(A)^2 + P(B)^2) = 1 - ((7/10)^2 + (3/10)^2) = 0.42
Then we apply rule 1, for example: weight > 0.2lbs, then we got:
left node: 5 apples and 1 banana
right node: 2 apples and 2 banana
GINI left = 1 - ((5/6)^2 + (1/6)^2) = 0.28
GINI right = 1 - ((1/2)^2 + (1/2)^2) = 0.5
Information gain = 0.42 - (6/10 * 0.28 + 4/10 * 0.5) = 0.05
The information gain 0.05 is a good indicator for how good the split is.
**Why it is generally possible to create an infinite number of trees?**
Because there are so many different paramater we can specify for decison tree, such as MaxDepth, GINI or Entropy, also there are many ways for feature representation, each combination above can create a unique tree.
2. Data Prep
Same cleaned sales dataset and testing / training spit method as NaiveBayes model training, however one difference is the data normalization steps are removed, since it’s not useful for DT training and can be confusing when we visualizing the tree.
Code Step: https://github.com/BraydenZheng/Product_Recommendation/blob/master/naivebayes/data_prepare.ipynb
Raw Data
Cleaned Data
3. Code
Decison Tree training and evaluation:
https://github.com/BraydenZheng/Product_Recommendation/blob/master/decision_tree/decision_tree.ipynb
4. Result
Tree 1
First tree using ‘gini’ as criteria, and max_depth set as 3, achieved the accuracy of 0.78.
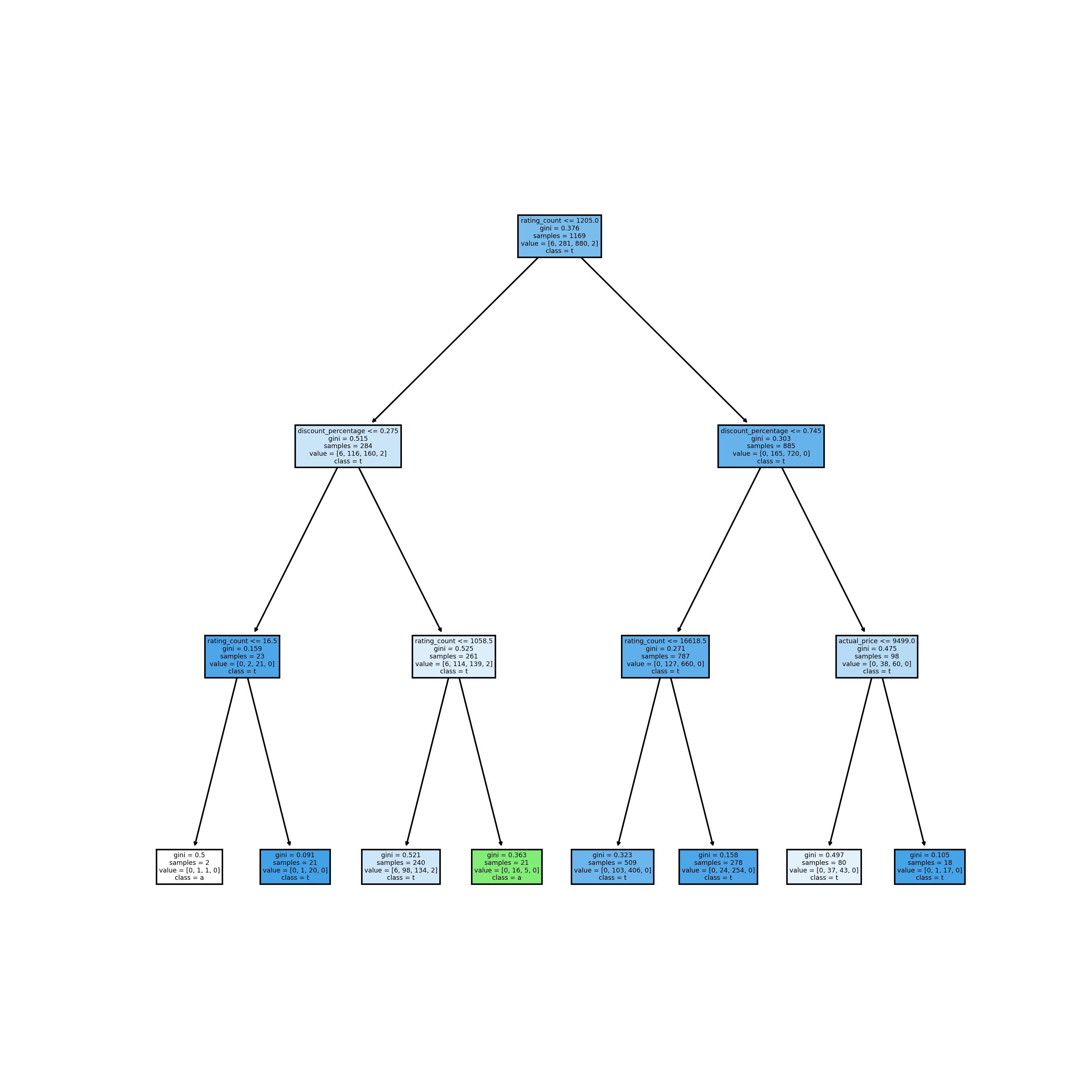
Tree 2
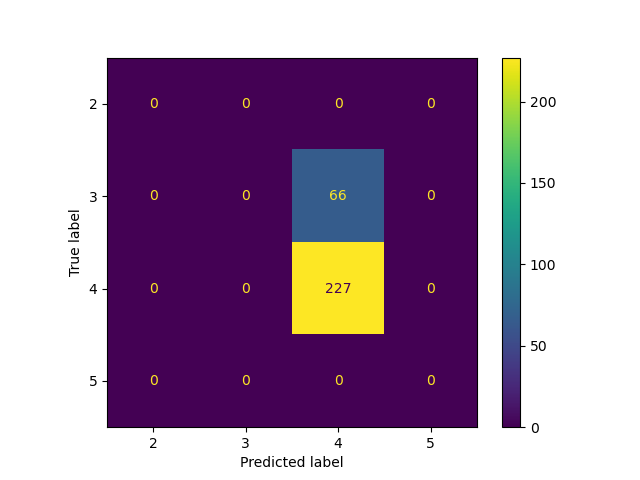
Second tree using ‘entropy’ as criteria, and max_depth set as 3, achieved the accuracy of 0.77.
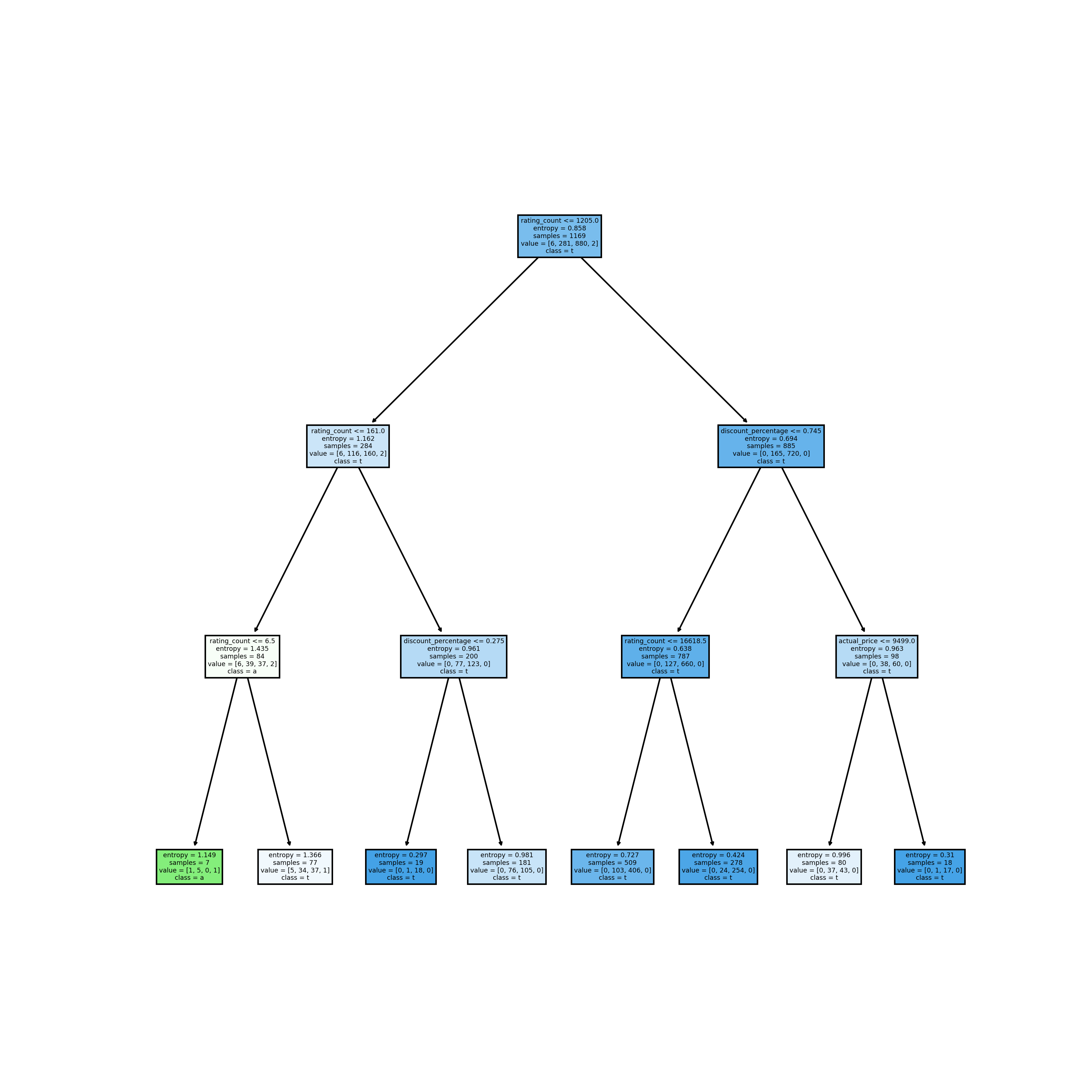
Tree 3
Third tree using ‘gini’ as criteria, and max_depth set as 5, achieved the accuracy of 0.78.
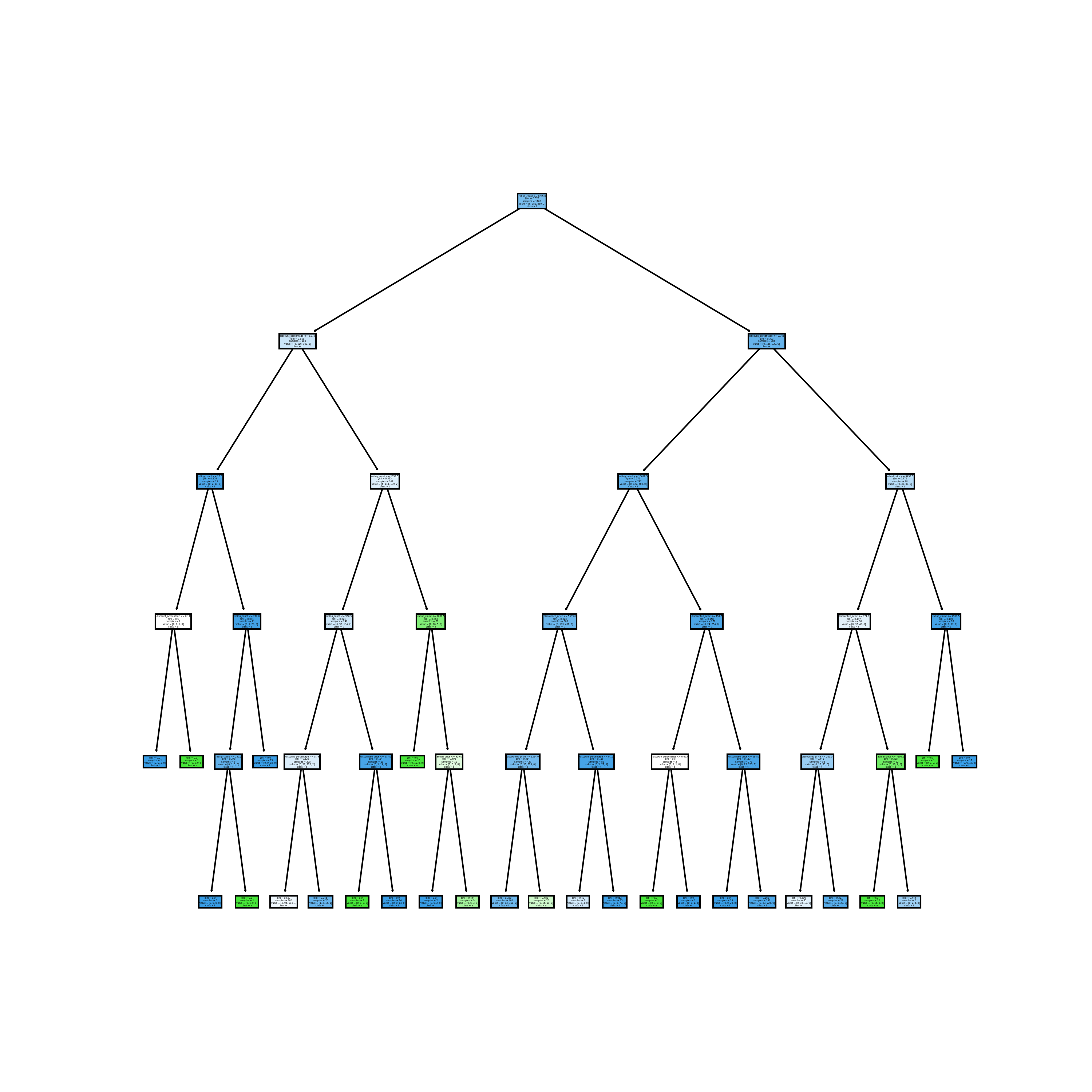
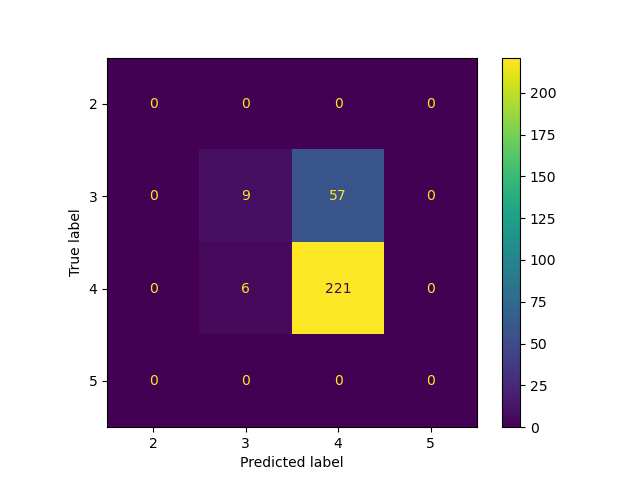
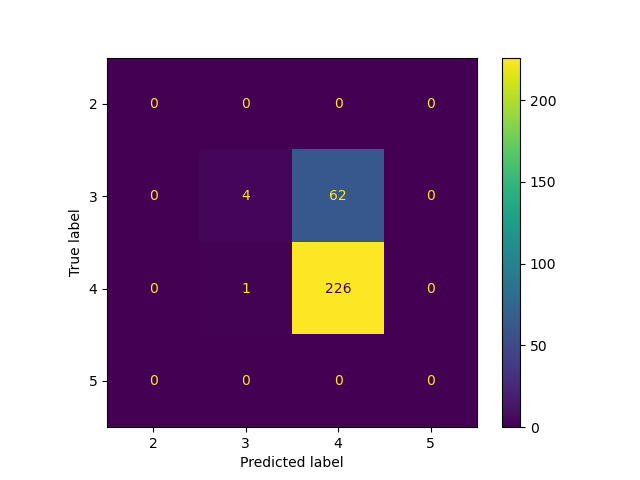
From three decison tree results above, we find they all get similar accuracy regardless of parameter setting, which is also close to the one got on NaiveBayes model. Genearlly decison tree has good performance on these numeric data, but training process takes lots of time, especially if we don’t limit the maxiumn depth.
5. Conclusion
Decison tree is a good way to be used for classification, and predicting the rating score in this dataset. We can use this model to predit how customer think about the existing or incoming products, and use these features for future predictions.
DecisonTree