1. Preface
Nowadays, people live in material word with so many choices overwhelming to the daily life, sometimes, finding an item simple as salt would be time-consuming when walking around a big supermarket. Categorize plays a big role to help us limit the search scope, making our searching more easily and quality.
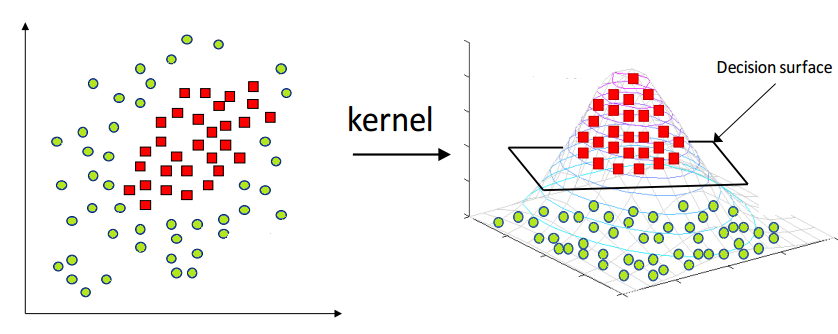
@Source: https://www.cleanpng.com/png-cluster-analysis-spectral-clustering-k-means-clust-1466403/download-png.html
2. Overview
The main object here is clustering / categorizing the best sell amazon book during 2009 ~ 2019, based on year, reviews, prices and other attributes, researchers can find sort of similarity between these books in different styles, customers can have a view of group type and find similar book based on their favourite.
@Source: image from paper Tom Tullis, Bill Albert, in Measuring the User Experience (Second Edition), 2013
Partitional Clustering
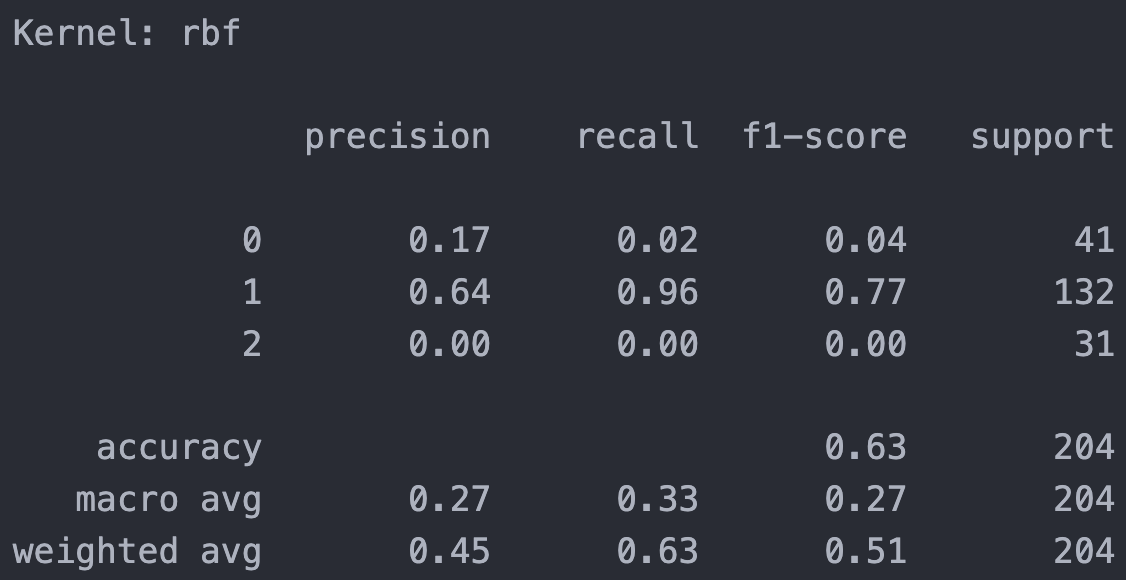
Implemented in python, using standard K-means alogrithm for the process, pick a couple of K choices, and use silhouette method and repeat experiment to ensure the clustering quality. Euclidean distance used.
Hierarchical Clustering
Implemented in R, using complete linkage clustering, generating the dendodiagram, and playing around different parameter seting to find a good clustering seperation. Cosine Similarity distance used.
3. Data Prep
For clustering data column, the dataset comes with user rating, number of reviews ,prices, years (publish) as original numerical data type. Besides, ‘Genere_n’ column (filled with value 0/1) will be created based on string type column genere, which indicates whether the book belongs to fiction, will also be used as clustering parameter. Finally, z-score normalization will be applied to some columns.
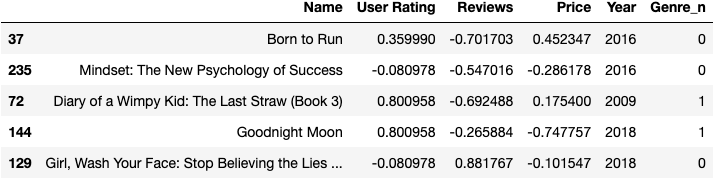
Detail for Data prepartion (Python):
https://github.com/BraydenZheng/Product_Recommendation/blob/master/clustering/data_prepare.ipynb
Link to sample data: book_clustering
4. Code
Code for K-means (Python): https://github.com/BraydenZheng/Product_Recommendation/blob/master/clustering/kmeans.ipynb
Code for Hierarchical Clustering (R): https://braydenzheng.github.io/clustering/skip_render/hierarchical.html
5. Result
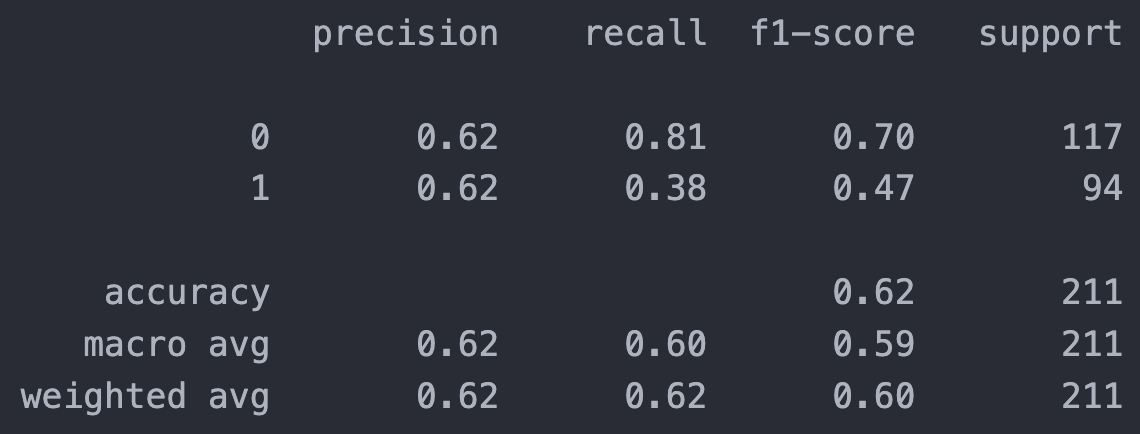
5.1 K-Means
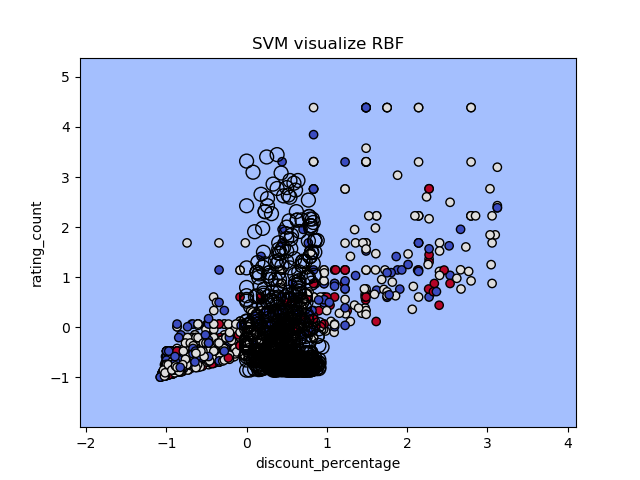
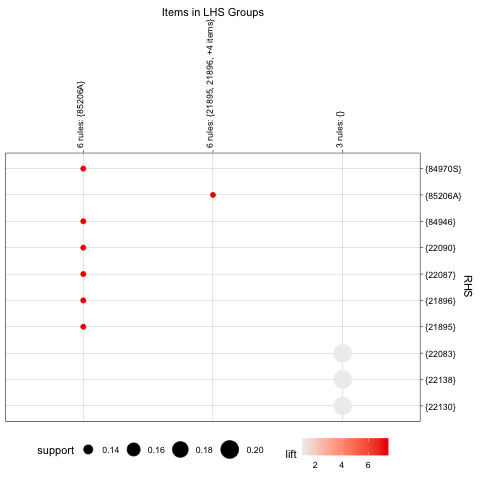
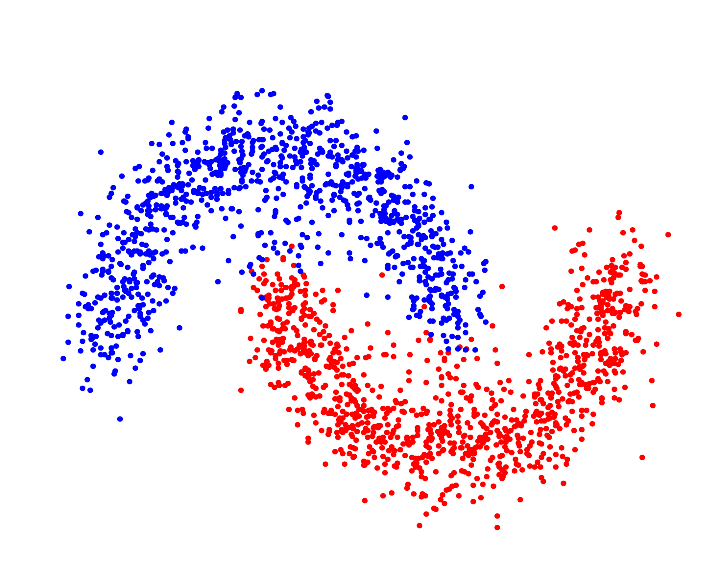
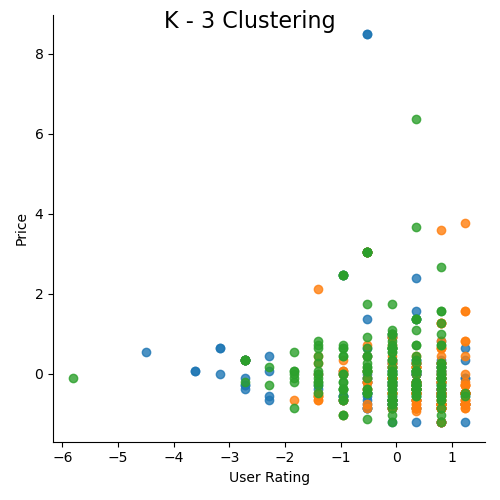
At the begining, I tried K = 3 for 5 dimension, althogh 5-D is hard to visualize, I still choose two feature (‘User rating’ and ‘Price’) to visualize the cluster. From picture above, we can see points dense in the center with overlap (500+ points in the graph), but still a clear outline for each cluster.
To further discover the best K, I used Silhouette score to try k value range between 3 and 21, and got the graph below.
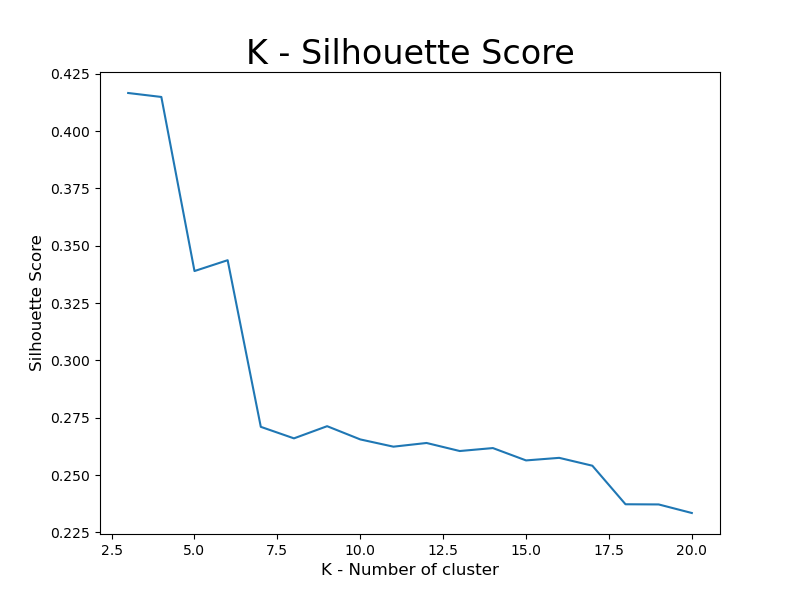
Looks like when K equal to around 3, we have best silhouette score, which also shows in the graph with highest score around 0.41. When it goes to 5 or 6, it still have silhouette score around 0.33 while maintaing a good number of clusters, which is a great balance between cluster number and silhouette score.
To visualize and decide the best K, I also plot the cluster image for K = 4, 5, 6. (I put 5 features for clustering, in order for plot 2-D, I only choose two features)
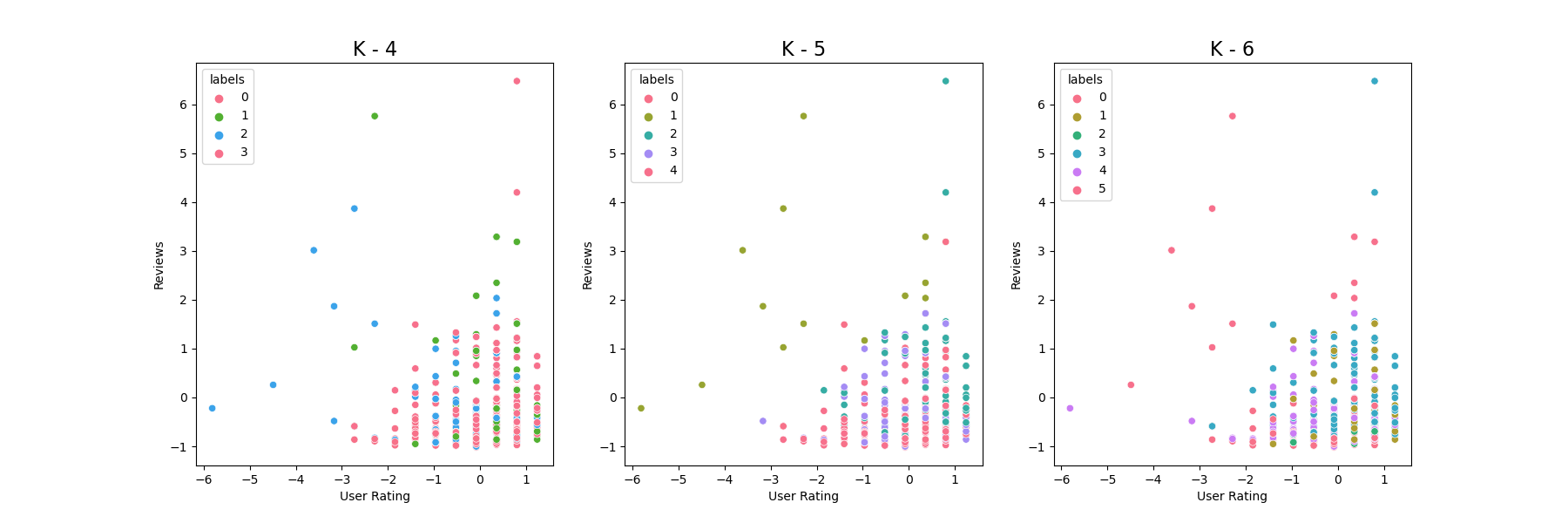
While it’s hard to determine the best K based on these 2-D graphs, and the three graphs do have dense points gathered in the middle, we still can find the border between each one especially for the outer part, becasue these 3 choices all have good silhouetee score and distribution, I will choose K equal to 6 for a cluster of total 550 books, which will be just on the average so that customer will not feel overwhlemdw with too many categories but also maintains a good variety.
5.2 Hierchical Clustering
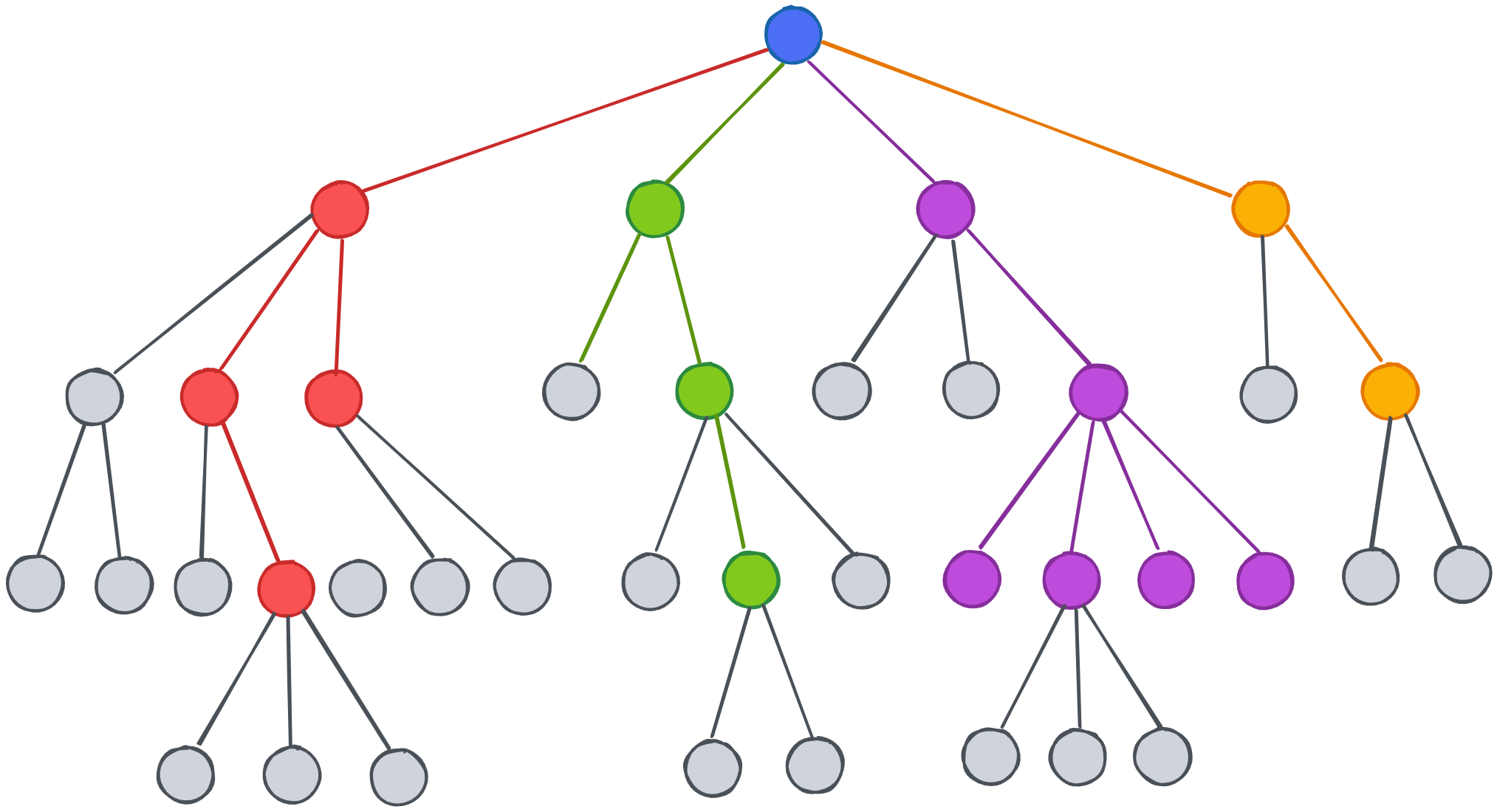
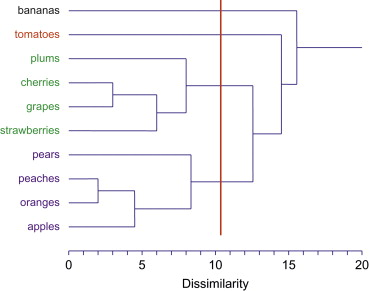
Similar setting is also used for hierarchical clustering, after applying cosine similarity as dist, I tried K as [5, 6, 7] for the clustering, and get graph results below.
K = 5
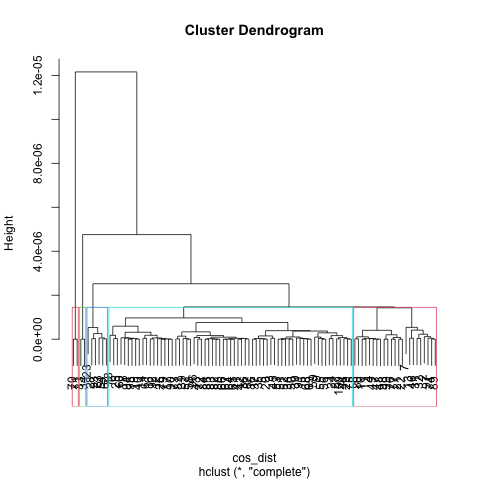
K = 6
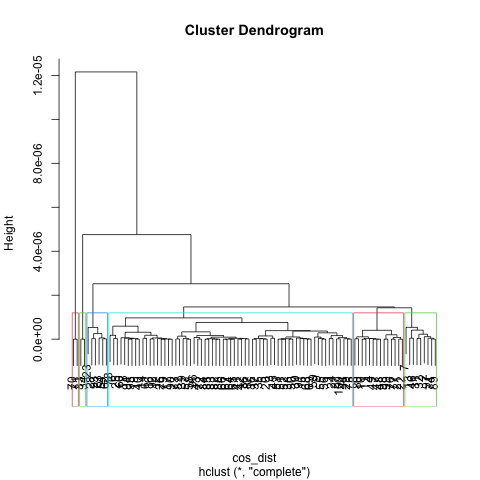
K = 7
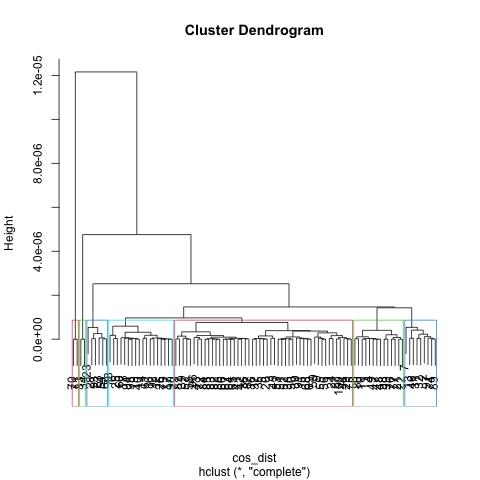
From visualization above, one common thing I observe is one cluster took majority of the space (Blue for K == 5, 6 and Red for K == 7). Regards to best K choice, I considered factors that make the tree balanced, having a suitable number of clusters that not too high or too low, also letting each cluster has similar size (keep variance low). K as 7 in this case did best in these valuation factor, which has a good representation of each category also balanced size of the tree.
Compare to K - means, the best K for two algorithms is pretty close (K-means is 6, hclust is 7). For choice in K-means, the silhouette coefficient plays an important role so I choose a small K which makes data points close to each other. For hclust, I consdier more about the tree balanced and its portion ‘big picture’, both of them lead to a similar result at the end.
Conclusions
It’s good practice to apply these two efficient methods for the book clustering, I learned different factors and consideration for find a best K value, that’s also find the number of category for the book recommendation actually. Sometimes, all these values, scores (Silhouette coefficient and tree height), even for distruibtion give us a reference for choosing the K - category, but make a final decison for both K and clustering usually requries extra consideration for business factors or the customer preference.